手把手教你使用pprof
大家好,今天我们来一起学习一下 pprof 这个工具。
pprof 是什么
肯定会有人问,pprof 是做什么用的?
pprof 是 Go 语言自带的性能分析工具,用于识别和解决应用程序中的性能瓶颈问题。大家应该或多或少有听说过 “三高代码”,这里的 “三高” 并不是指 “高血压、高血糖、高血脂”,而是指 ”高性能、高并发、高可用“,而 pprof 就可以帮助我们写出这样的 “ 三高代码 ”。
在正式介绍 pprof 之前,我们先来解释一下三高的含义,以及需要注意的点:
- 高性能:由于我们电脑组件的执行速度 CPU > 内存 > 磁盘,想要写出高性能的代码,就要优先让 CPU 去处理核心逻辑。像 io 操作这类耗时且不太核心的逻辑,比如 日志打印、日志保存,就不需要去关注它的执行速度 。我们可以将 io 操作,放在消息队列里面去缓慢执行,我们不关心它什么时候完成,只需要最后能够完成就行了。这样,我们就可以让 CPU 更多的时间去处理业务的核心逻辑。再者就是采用合适的算法和数据结构进行优化,这里需要具体情况具体分析,就不做多的解释了。总结一下就是,避免 io 操作,采用合适的算法和数据结构。
- 高并发:Go 语言本身就更利于高并发的实现,可以充分利用 CPU 资源,但我们也需要注意避免阻塞,因为这会导致 CPU 的调度工作增加,程序上的体现就是程序执行缓慢。同样的,由于 io 并不支持并发,如果你的代码中涉及到了 io 操作,即使是并发执行的,也会退化成同步执行。总结一下就是,避免阻塞、避免 io 操作,io 不支持并发。
- 高可用: 比如 session sookie 机制,就不支持多机部署,我们的代码最好是无状态的,这样从才能支持高可用。总结一下就是,避免状态,使应用程序变成无状态程序。
如何使用 pprof
pprof 本质上就是一个工具,我们在写完代码之后,可以借助 pprof 对我们的程序进行性能指标的采集,采集的方式也有好几种,下面我们会介绍三种,分别是 web 网页采集、基准测试采集、硬编码采集。采集到对应的信息后,再借助 pprof 提供的工具 go tool pprof 进行性能分析,进而确定造成性能瓶颈的地方,对代码进行优化。
性能指标
下面我们先来介绍一下 pprof 一些常见的性能指标:
- allocs:
- 功能:查看过去所有的内存分配信息
- 用途:用于分析程序的内存分配情况,找到可能导致内存泄漏或者不必要的大内存分配代码
- block:
- 功能:查看导致同步原语阻塞的堆栈跟踪信息
- 用途:用于识别程序中的同步阻塞点,找到潜在的并发瓶颈
- cmdline:
- 功能:查看当前应用程序的命令行完整的调用路径
- 用途:用于了解应用程序的启动参数和调用路径
- goroutine:
- 功能:查看当前所有的协程堆栈跟踪信息
- 用途:用于了解当前程序中所有运行的协程,以及它们的堆栈信息
- heap:
- 功能:查看活动对象的内存分配情况
- 用途:用于分析程序的堆内存分配情况,找到可能导致内存泄漏或者不必要的大内存分配的代码
- mutex:
- 功能:查看互斥锁的竞争持有者的堆栈跟踪信息
- 用途:用于识别程序中互斥锁的竞争情况,找到可能的并发瓶颈
- profile:
- 功能:CPU 的使用报告
- 用途:用于分析程序的 CPU 使用情况,找到可能导致性能瓶颈的代码
- threadcreate
- 功能:查看新线程的堆栈跟踪信息
- 用途:用于了解程序中新线程的创建情况,以及它们的堆栈信息
- trace:
- 功能:整个应用程序的调用的堆栈信息
- 用于了解整个应用程序的调用路径和函数调用关系
知道了各项性能指标的功能以及用途,接下来我们来看看如何采集对应这些性能指标吧~
三种性能指标采集方式
这里介绍的三种不同的采集方式,是指生成对应的信息的方式不同,但最终都是需要通过 pprof 工具对采集到的信息文件进行分析的。
准备工作
在采集信息之前,我们先写一些有问题的代码,以模拟我们平时的问题代码。
在根目录中,创建 data 目录,然后在 data 目录下创建一个 data.go 文件,在里面定义一个接口,以供我们写一些其他代码:
1 | |
然后再在 data 目录下,分别创建 block、cpu、goroutine、mem、mutex 目录,以及对应的 .go 文件。
下面我们来分别看看对应的 .go 文件中的内容,以及它们的作用:
block.go
1 | |
这里通过将程序睡眠一秒钟,来模拟一些需要等待的操作。
cpu.go
1 | |
这段代码通过循环 100 亿次,来模拟不断消耗 CPU 的场景。
goroutine.go
1 | |
这里通过创建 10 个协程,并让每个协程睡眠 30 秒,以保证每个时刻都有协程处于活跃状态。
mem.go
1 | |
这段代码通过不断往 buffer 中分配内存,来模拟实际程序中分配内存的情况。只要内存小于 1 个 G,就每次新分配 1 M。
这里的单位是定义在一个新的目录 constants 中的 constants.go 文件里的,代码如下:
1 | |
mutex.go
1 | |
这里通过加锁两次、解锁一次,来模拟程序死锁的情况。
至此,我们的准备工作都完成了,下面就开始介绍如何采集信息了。
web 网页采集
我们在项目根目录下创建 main.go 文件,由于是 web 网页采集,所以我们需要起一个 web 服务,然后再去采集该服务的信息。在监听服务前,我们需要开启对锁调用以及对阻塞操作的跟踪,不开启的话抓不到,代码如下:
1 | |
通过将之前准备好的各种指标的模拟函数封装到 cmds 里,然后循环调用 200 次,来模拟我们真实的应用程序环境。
然后我们运行 go run main.go ,再浏览器中访问 http://localhost:6060/debug/pprof/ 就能看到我们上面介绍过的性能指标了。
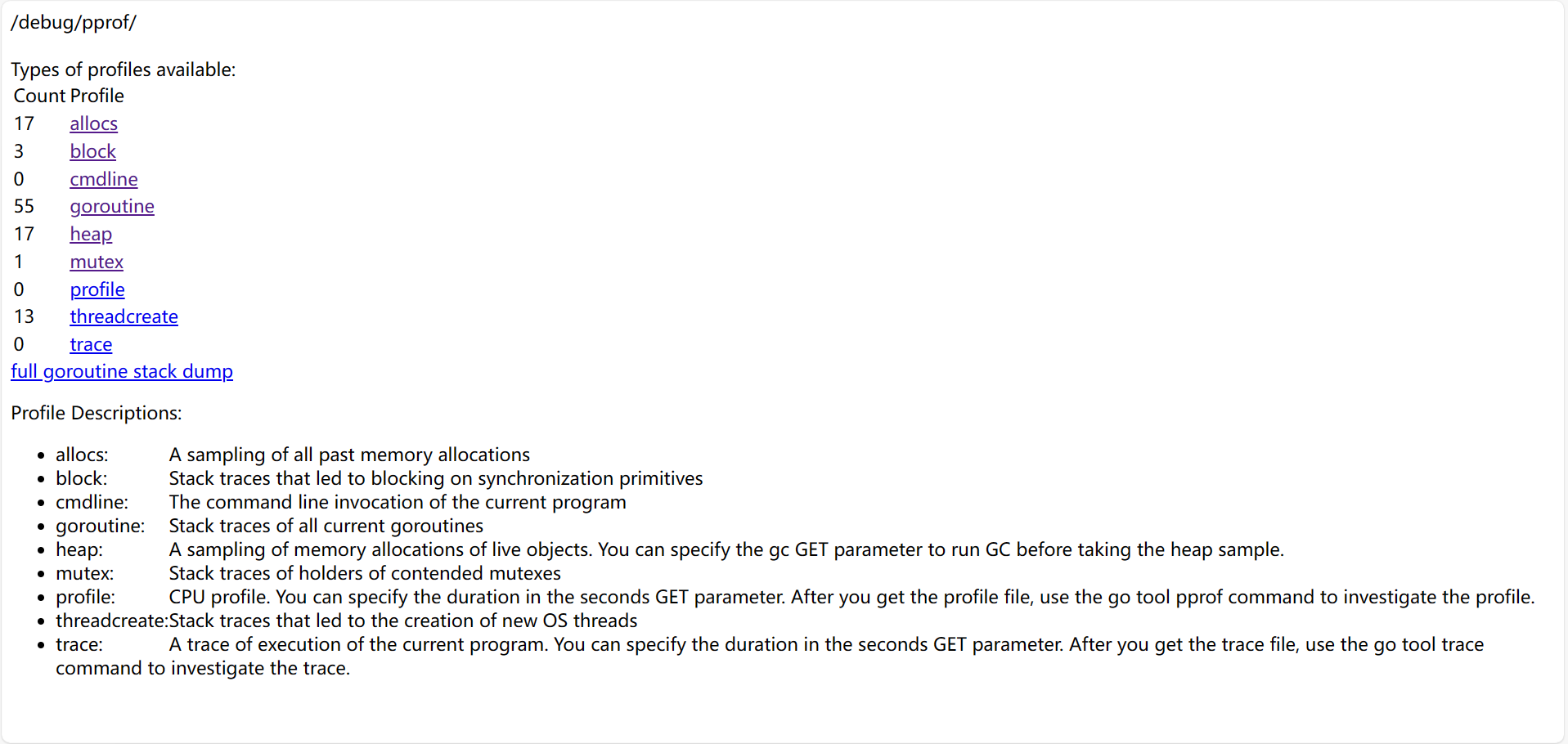
我们可以点击到对应的指标进行查看,会发现这种形式我们很难看懂。这个时候,我们可以先点进某个指标的对应页面,比如 allocs,可以看到浏览器中的网址是 localhost:6060/debug/pprof/allocs?debug=1 我们把网址中的 ?debug=1 删除,并点击回车,浏览器就会自动帮我们下载对应的文件到我们电脑上,这样我们就获得了该项性能指标的数据了。其他指标也是同样的操作方式,需要强调的是对于 profile , 点击它,pprof 会默认采集 30 s 数据,并在采集完成后自动将信息下载电脑上。至于怎么分析,我们后面再来介绍。
基准测试采集
现在我们再来看看第二种采集方式 —— 基准测试采集。其实本质上就是利用性能测试,然后将对应测试的结果以文件的形式输出到对应的目录下保存,然后再对这些采集到的数据用 pprof 工具进行分析即可。关于性能测试方面的知识,可以查看 手把手教你写单元测试 - 胤凯 (oyto.github.io) 这篇文章。下面我就直接带大家简单的过一下,利用性能测试采集的代码怎么写就行了。
为了方便,我们的基准测试就直接调用之前写好的各类指标的 Run 方法。同样我们在项目根目录下创建一个 data_test 目录,然后创建一个 data_test.go 文件,在里面粘贴我们的基准测试代码即可:
1 | |
然后 在 根目录下创建 testout 目录,用于存放我们采集的信息,并在命令行运行 go test -run ^$ -bench . ./data_test/ -blockprofile block.out -cpuprofile cpu.out -memprofile mem.out -mutexprofile mutex.out -trace trace.out -outputdir ./testout 。
等待一段时间后,基准测试完成之后,就可以看到采集到的信息已经全部在 testout 中存放了。我们可以试着打开这些文件看一下,会发现是乱码,无法直观的看到对应指标的信息到底是怎么样的。所以我们还是需要通过 pprof 提供的工具进行分析。
硬编码采集
硬编码采集其实和基准测试是差不多的,只是需要我们自己去写对应的采集代码的逻辑,并将采集的信息保存到指定的位置。同样最后,也是需要使用 pprof 工具才能进行分析。
我们在项目根目录创建 code_coolection 目录,在该目录下创建 out 目录和 main.go 文件,并将下面的代码粘贴到 main.go 文件中:
1 | |
上面的代码可以分为三部分:
- 开启一些必要日志输出和锁调用以及阻塞操作调用的跟踪
- 编码采集 cpu、mem、trace 信息,并将采集的信息保存下来
- 利用之前实现好的接口,模拟业务代码
三种采集方式的对比
web 网页采集
- 优点:
- 实时可视化: 提供实时的可视化界面,便于直观观察应用程序的性能。
- 交互式分析: 可以通过图形化界面进行交互式的性能分析,查看不同性能指标的详细信息。
- 方便易用: 无需修改代码,通过 HTTP 请求即可触发性能数据采集。
- 缺点:
- 实时性: 不适合长时间运行或对实时性要求较高的生产环境,因为需要手动访问页面。
- 可控性较差: 无法在代码中控制何时开始和结束性能采集。
- 适用场景:
- 开发和测试阶段: 用于开发人员和测试人员在开发、测试过程中对性能进行快速分析和调试。
基准测试采集
- 优点:
- 可编程: 可以通过编写基准测试函数,并使用
testing包进行性能采集。 - 自动化: 可以在测试套件中自动运行性能测试,方便集成到持续集成流程中。
- 可编程: 可以通过编写基准测试函数,并使用
- 缺点:
- 需要额外编写测试代码: 需要编写专门的基准测试代码,不能直接在生产环境中使用。
- 适用场景:
- 持续集成: 适用于集成到持续集成流程中,每次构建运行性能测试。
硬编码采集
- 优点:
- 灵活性: 可以在代码中灵活选择何时何地采集性能信息,对采集内容有更大的控制权。
- 定制性高: 可以选择性采集特定的性能信息,更符合定制化需求。
- 缺点:
- 需要手动编码: 需要在代码中手动添加采集性能信息的逻辑。
- 生产环境谨慎使用: 在生产环境中需要慎重使用,避免因为性能采集导致系统负载过大。
- 适用场景:
- 定制化需求: 需要根据具体场景定制性能采集逻辑的情况。
总结:
- Web 网页采集: 适合开发和测试阶段,用于快速观察和调试。
- 基准测试采集: 适用于集成到持续集成流程,自动运行性能测试。
- 硬编码采集: 适用于需要灵活控制采集逻辑,以及特定场景下的性能调试。
如何分析采集到的信息
收集到的信息一般都会保存在一个文件中,我们找到该文件,使用 pprof 提供的工具就可以进行分析了。
我们以 cpu.out 文件为例,在命令行中切换到该文件对应的目录,然后使用 go tool pprof cpu.out ,然后就可以进入到交互模式。
top 命令
我们可以使用 top 命令, 执行 top 命令后,会在命令行中输出当前的 CPU 消耗排行榜,显示消耗 CPU 最多的函数,帮助快速定位 CPU 使用率最高的部分,默认显示 10 条。可以通过添加参数 top n 来控制输出的条数。
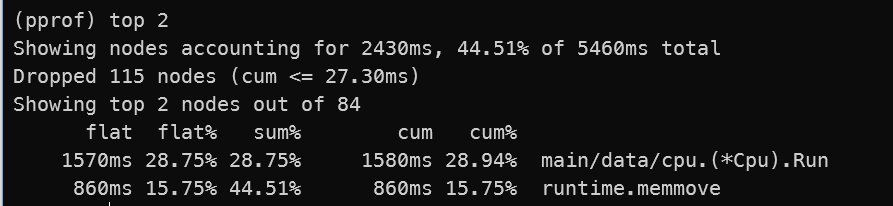
- flat:函数自身运行的资源消耗
- cum:当前函数加上所用调用栈
list 命令
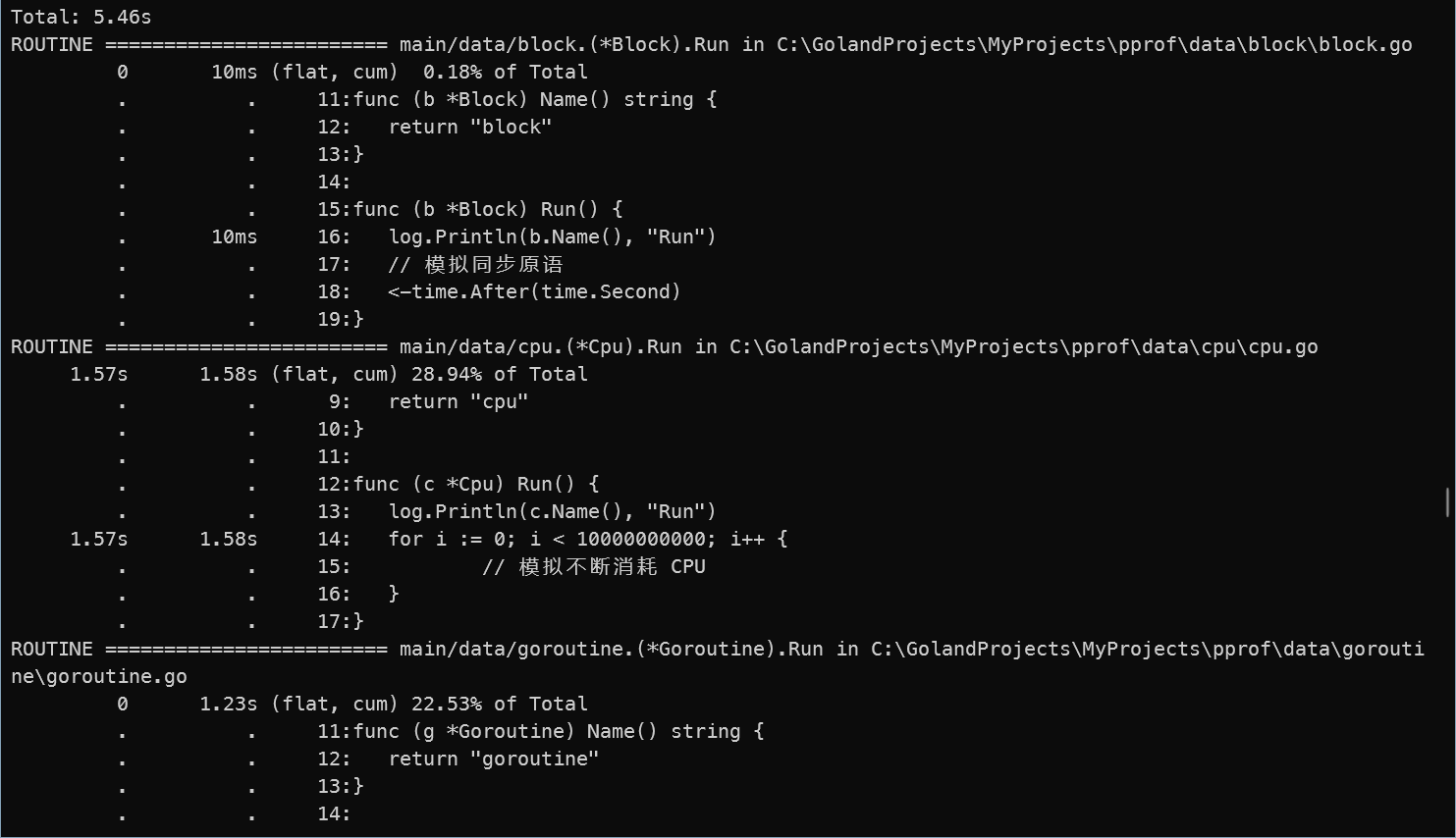
也可以使用 list Run 命令,执行后会在命令行中输出与函数 Run 相关的源代码,方便我们快速查找到有问题的源代码所在地,这对于进一步分析和优化性能问题很有帮助。
web 命令
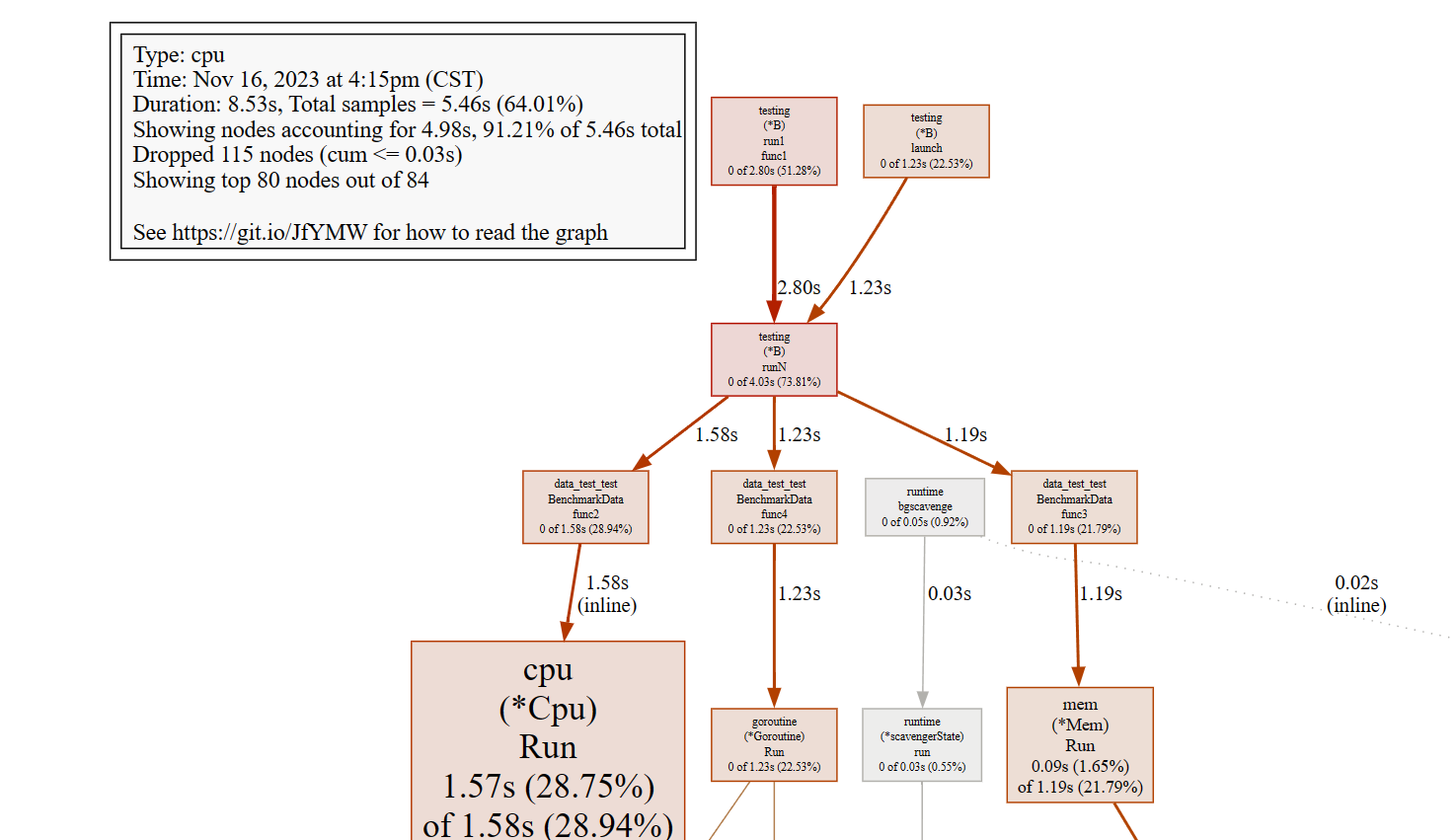
想使用 web 命令,需要我们先去下载一个插件 Download | Graphviz ,找到对应的系统进行安装,并在配置好环境变量。
同样使用 go tool pprof cpu.out 进入交互模式,在交互模式下输入 web ,然后会生成一张 svg 格式的图片,并会默认在浏览器中打开。这张图以图形化的方式展示程序中各个函数的调用关系和执行时间。通过这个该图,你可以迅速定位程序的性能瓶颈。深色、宽度较大的块通常表示执行时间较长的函数,可能是需要优化的部分。
ui 方式查看
我们还可以使用 go tool pprof -http :8080 cpu.out 这种方式指定一个端口进行查看。
这种方式会在本地启动一个 HTTP 服务器,并在浏览器中显示性能分析的交互式界面。我们可以通过浏览器直观地浏览性能分析数据,而不必依赖终端界面,而且我们可以将性能分析页面的 URL 分享给其他人,方便团队成员共同分析和解决问题。更为重要的是,-http 方式提供了实时更新的功能。当程序在运行时采集数据,浏览器中的页面会及时反映这些数据的变化。
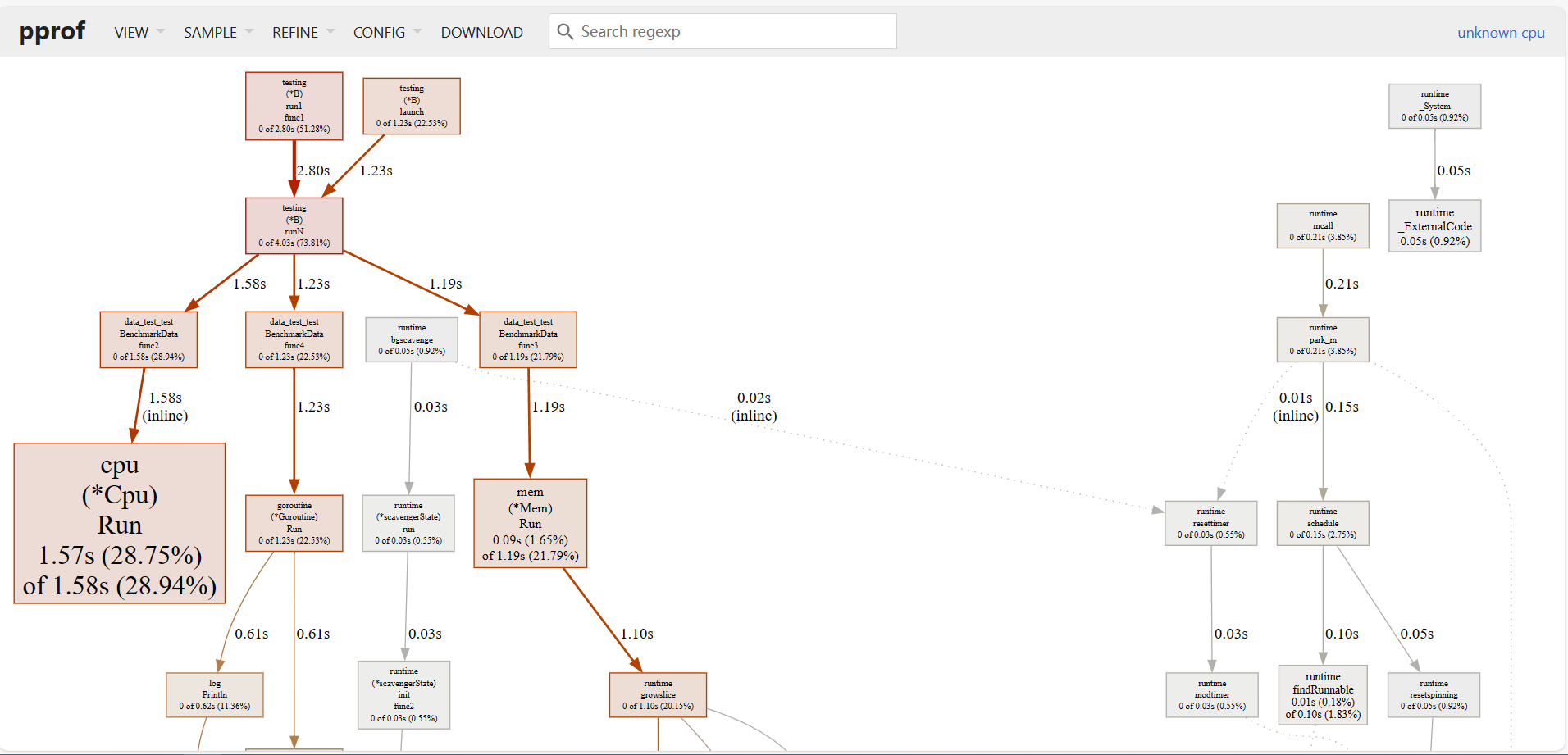
其实 ui 方式,就是将命令行下一些参数所显示的信息,通过图形界面向我们展示。比如:
VIEW
VIEW 下的选项:
- top:
- 作用: 显示性能分析的顶级函数列表,按照 CPU 使用时间排序。
- 用途: 用于查看程序中占用 CPU 时间最多的函数,帮助确定性能瓶颈。
- graph:
- 作用: 生成并显示调用图(call graph)。
- 用途: 提供了函数之间调用关系的可视化,有助于理解代码的调用流程。
- flame Graph:
- 作用: 生成并显示火焰图。
- 用途: 火焰图是一种可视化工具,直观显示函数调用关系和执行时间,更容易发现性能瓶颈。
- peek:
- 作用: 显示函数的源码和汇编码。
- 用途: 提供了在源码和汇编级别查看函数的功能,用于深入分析函数执行过程。
- source:
- 作用: 显示函数的源码。
- 用途: 提供了在源码级别查看函数的功能,便于理解代码的具体实现。
- disassemble:
- 作用: 显示函数的汇编码。
- 用途: 提供了在汇编级别查看函数的功能,有助于深入了解函数的底层执行过程。
SAMPLE
SAMPLE 下的选项:samples 和 cpu 是两个常用的命令,用于查看不同类型的性能样本信息。
- samples:
- 作用: 表示程序在采样时的状态信息,记录了堆栈跟踪信息和对应的采样计数。
- 用途: 用于采样分析,通过收集一系列采样数据,可以了解程序在不同时刻的执行情况,帮助找出热点代码和性能瓶颈。
- cpu:
- 作用: 表示 CPU 使用时间的信息,记录了每个函数的 CPU 使用时间和调用次数。
- 用途: 用于 CPU 时间分析,提供了函数级别的 CPU 使用情况,帮助确定哪些函数占用了大量的 CPU 时间,从而找到潜在的性能问题。
REFINE
REFINE 下的选项:focus、ignore、hide、show、show from、reset 是用于调整视图的命令。它们的作用如下:
- focus:
- 作用: 将视图聚焦于指定的函数,只显示与该函数相关的信息。
- 用途: 用于关注某个特定函数,查看与该函数相关的性能信息,便于深入分析该函数的性能状况。
- ignore:
- 作用: 忽略指定函数,不显示与该函数相关的信息。
- 用途: 用于排除某些函数,以便在性能分析中聚焦于其他关键函数,减少视图的干扰。
- hide:
- 作用: 隐藏指定函数及其调用图,不显示在视图中。
- 用途: 用于在视图中隐藏一些不感兴趣或者不重要的函数,简化视图。
- show:
- 作用: 显示之前被隐藏的函数。
- 用途: 用于取消之前使用
hide命令隐藏的函数,重新在视图中显示。
- show from:
- 作用: 从指定函数开始显示调用图。
- 用途: 设置一个起始点,从该点开始显示函数的调用图,有助于查看特定路径的调用关系。
- reset:
- 作用: 重置视图,取消之前的
focus、ignore、hide等操作。 - 用途: 用于还原视图到最初的状态,清除之前的调整,重新全面查看性能信息。
- 作用: 重置视图,取消之前的
这些命令提供了在交互模式下调整视图的灵活性,使用户能够更好地根据具体需求选择和排除函数,以获取更有针对性的性能分析信息。
CONFIG
CONFIG 下的选项:Save as … 和 Default 是在 Web UI中的一些配置选项。作用如下:
- Save as …: 这个选项允许您保存当前的配置为一个命名的配置文件。配置文件包含了视图布局、颜色方案等信息。通过保存配置,您可以在将来重新加载相同的配置,方便重复使用。
- Default: 这个选项是将当前的配置设置为默认配置。默认配置会在下次打开
go tool pprof时自动加载。这对于您希望在多次运行中使用相同的配置时很有用。
这两个选项的目的在于提供一种灵活的方式,使用户能够保存和恢复他们喜欢的配置,或者设置一个默认配置以简化工作流。这对于在不同的分析任务之间切换,或者在不同的会话中保持一致的可视化设置都很有帮助。
DOWNLOAD
Download 选项允许您下载当前的图形化展示或报告。下载之后,会生成一个 .pb 文件,同样需要配合 go tool pprof 使用。
小结
这篇文章,带大家了解了 pprof 工具,并带大家熟悉了 pprof 工具的使用方法,相信大家在未来一定会使用到这款工具的,毕竟一位优秀的程序员,写出来的代码一定是 “三高” 代码。